Power Automate Desktop(PAD)で、同じIDを持つ複数行のデータを1行にまとめたい(グループ化したい)場面は多いですよね。
しかし、いざ作ってみると「Excelが裏で残り続ける」「データテーブルの挙動が謎でエラーが出る」といった壁にぶつかりがちです。
本記事では、実務でそのまま使える「安定性・高速性・保守性」を兼ね備えた集約フローを徹底解説します。
1. 実現したい処理のイメージ
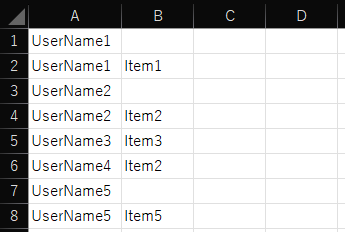
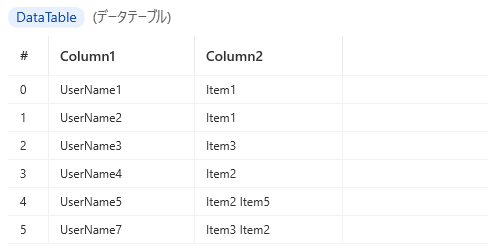
以下のように、左列(ID)が同じデータの右列(値)を、スペース区切りで1行に集約します。
<集約前>
<集約後>
2. フロー全体の構成
このフローは大きく「エクセルデータの読込」と「データ整形」の2つのブロックで構成されています。
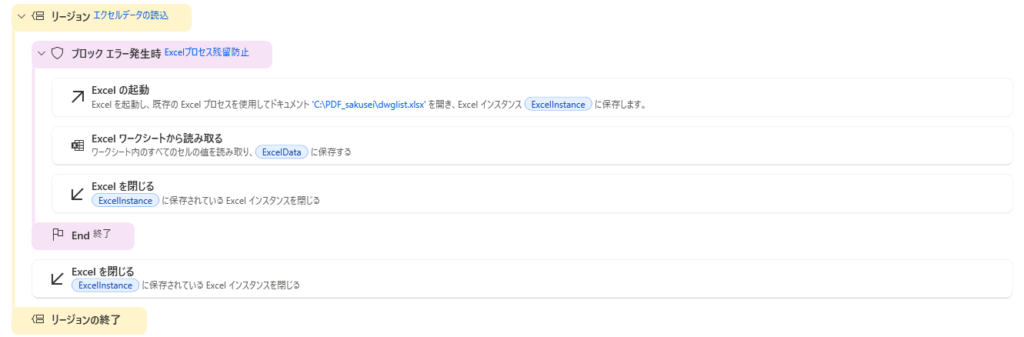
ステップ1:Excelプロセス残留防止
・ Excelインスタン表示をOFF(処理時にエクセル画面表示しない)とし、高速化を図っています。(ただし、クラッシュ時の非表示プロセス残留防止要)
・ 非表示プロセス残留防止のため、ExcelプロセスはBLOCK アクションで囲み、エラー時に確実に「Excelを閉じる」が実行されるようにしています。
ステップ2:データ整形ロジック
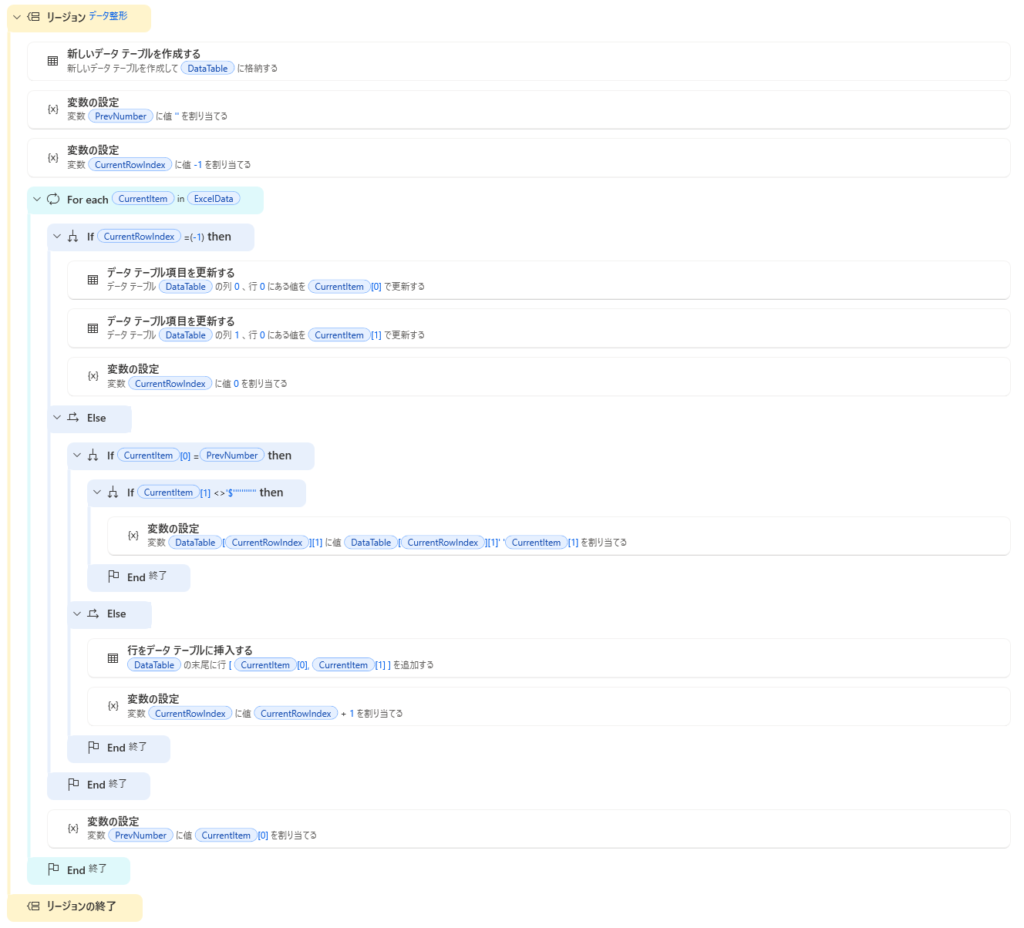
・ 「1つ前の行」と比較しながら、新しいデータテーブルを構築していきます。
・ PADのデータテーブルは最後の1行を消すと列情報まで消える「0行の壁問題」があるため、最初から1行目を設定しておくのが安全です。
・ 「全行から検索して結合」という力技を避け、上から順に見ていくだけで集約が終わるアルゴリズムとしています。
・ Excelに空白セルがある場合、そのまま結合すると不要なスペースが重なるため、結合処理の実施条件を「$”’%”%”’(空文字)」としています。
3. コピペ用コード
**REGION エクセルデータの読込
BLOCK Excelプロセス残留防止
ON BLOCK ERROR
END
Excel.LaunchExcel.LaunchAndOpenUnderExistingProcess Path: $'''C:\\PDF_sakusei\\dwglist.xlsx''' Visible: False ReadOnly: True UseMachineLocale: False Instance=> ExcelInstance
Excel.ReadFromExcel.ReadAllCells Instance: ExcelInstance GetCellContentsMode: Excel.GetCellContentsMode.TypedValues FirstLineIsHeader: False RangeValue=> ExcelData
Excel.CloseExcel.Close Instance: ExcelInstance
END
Excel.CloseExcel.Close Instance: ExcelInstance
ON ERROR
END
**ENDREGION
**REGION データ整形
Variables.CreateNewDatatable InputTable: { ^['Column1', 'Column2'], [$'''''', $''''''] } DataTable=> DataTable
SET PrevNumber TO $'''%''%'''
SET CurrentRowIndex TO -1
LOOP FOREACH CurrentItem IN ExcelData
IF CurrentRowIndex = (-1) THEN
Variables.ModifyDataTableItem DataTable: DataTable ColumnNameOrIndex: 0 RowIndex: 0 Value: CurrentItem[0]
Variables.ModifyDataTableItem DataTable: DataTable ColumnNameOrIndex: 1 RowIndex: 0 Value: CurrentItem[1]
SET CurrentRowIndex TO 0
ELSE
IF CurrentItem[0] = PrevNumber THEN
IF CurrentItem[1] <> $'''$\'\'\'%''%\'\'\'''' THEN
SET DataTable[CurrentRowIndex][1] TO $'''%DataTable[CurrentRowIndex][1]% %CurrentItem[1]%'''
END
ELSE
Variables.AddRowToDataTable.AppendRowToDataTable DataTable: DataTable RowToAdd: [CurrentItem[0], CurrentItem[1]]
SET CurrentRowIndex TO CurrentRowIndex + 1
END
END
SET PrevNumber TO CurrentItem[0]
END
**ENDREGION
4. まとめ
このフローのポイントをまとめると以下の通りです。
- Excelの高速化: インスタンス参照なしとしている。※エラー終了時のプロセス残留防止措置要
- Excelの残留防止:
BLOCKとON ERRORで確実に閉じる。 - データテーブル集約の高速化: 全体検索せず「前の行」と比較するロジックを採用。
- データテーブルの仕様攻略: 最初の空行を「上書き」して列定義を守る。
この構成をテンプレートとして持っておけば、Excelデータの集約作業が劇的に安定・高速化します。ぜひ活用してみてください!


コメント